12. Limitations to database modelling
Let’s say we have a CSV file that looks like this:
id,source,type,start,stop Gene1,Chromosome,Sanger,190,255 Gene2,Chromosome,Sanger,375,566 Gene3,Chromosome,Sanger,780,980 Gene4,Plasmid,Sanger,558,696 Gene5,Plasmid,Sanger,786,888
We can put this data into a table like this:
CREATE TABLE csv_data ( pk SERIAL PRIMARY KEY, id VARCHAR(256), source VARCHAR(256), type VARCHAR(256), start INT, stop INT );
Relationship databases work best when they’re modelling structured data that we can break down into these different relationships and attributes.
What if our data are sound files, images etc? Binary data is a form of unstructured data and this presents a challenge.
Postgres does provide a type called a blob for a binary large object, and we can use that to store binary data. Alternatively, we could leave the binary data in our file system and then use something like a varchar to store the location of the file on the file system.
Neither of these two solutions present us with a way of trivially indexing and searching the contents of those files.
If we have access to sufficient manpower or a sophisticated image recognition or a sophisticated audio recognition, we might be able to annotate the files with some related metadata.
We might be able to automatically discover the author, year of release, or in the case of images, what objects are within the image. We could then instead store this data in the database and make that easily searchable and retrievable.
Related to this is a document storage issue. It’s very easy to extract text from text documents but any sufficiently complex document such as a legal contract, is not easily summarised using only relational database tables.
Also, any sufficiently large documents store is likely only to be useful to your users if you will offer completely free text search throughout all of the texts and the documents.
Social network example
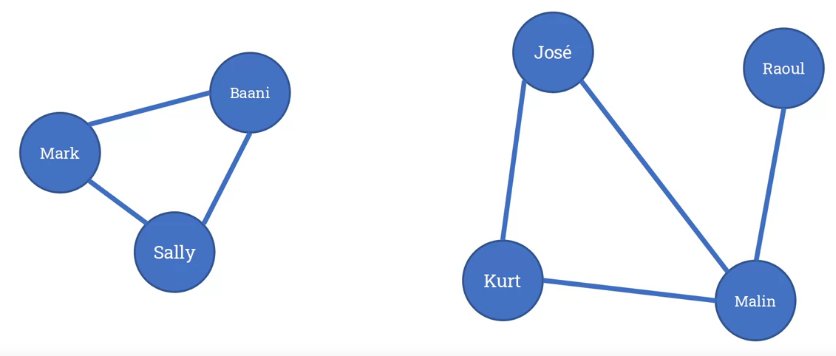
Here’s an example of a social network. How could we model this in a database?
Our first network has only three nodes, so the maximum possible of unique connections any node can have is two. Our second network has four nodes, and so the maximum number of unique connections is three. We can think about how would we represent this in our database; we could create a new table.
CREATE TABLE three_node ( pk SERIAL PRIMARY KEY, id VARCHAR(256) NOT NULL, first_connection_pk INT, second_connection_pk INT );
To represent the second network:
CREATE TABLE four_node ( pk SERIAL PRIMARY KEY, id VARCHAR(256) NOT NULL, name VARCHAR(256), first_connection_pk INT, second_connection_pk INT, third_connection_pk INT );
This doesn’t seem very satisfactory as the number of connections is arbitrary.
A better way is to create a table for people (the nodes), a table for connections (the edges) and also a tree table which records the relationships:
CREATE TABLE people (pk SERIAL PRIMARY KEY, id VARCHAR(256) NOT NULL); CREATE TABLE connections (first_pk INT, second_pk INT); CREATE TABLE tree (pk SERIAL PRIMARY KEY, name VARCHAR(256) NOT NULL, parent_one_pk INT, parent_two_pk INT);
Wednesday 27 October 2021, 558 views
Next post: 13. Good practice in relational database design Previous post: 11. Building a database using SQL
Advanced Web Development index
- 38. Writing API tests
- 37. Testing in Django
- 36. Class-based views in the Django REST framework
- 35. Building a RESTful web service in Django
- 34. Introduction to CRUD, REST and APIs
- 33. Refactoring with generic views in Django
- 32. Django validators
- 31. Django forms (2) – using the ModelForm class
- 30. Django forms (1)
- 29. JavaScript basics
- 28. Adding CSS to the template
- 27. Django templating
- 26. Deleting and updating records
- 25. Joins, filters and chaining commands
- 24. Using the ORM in views.py
- 23. Adding to the database by writing a script
- 22. Adding to the database with Django Admin
- 21. Migrations
- 20. ORM – work through example
- 19. An introduction to the Object-Relational Mapper
- 18. Altering the database
- 17. SQL functions and summaries
- 16. SQL Query performance
- 15. Queries and table joins in SQL
- 14. Inserts and queries in SQL
- 13. Good practice in relational database design
- 12. Limitations to database modelling
- 11. Building a database using SQL
- 10. Introduction to PostgreSQL
- 9. How to start writing a new application in Django
- 8. Building a lightweight project
- 7. Django URLs
- 6. Django templates
- 5. Django models
- 4. Django views
- 3. Creating a new hello app
- 2. Creating a new virtual environment
- 1. Setting up Django
Leave a Reply