34. Introduction to CRUD, REST and APIs
34.01 Introduction to CRUD
CRUD is an acronym for the four functions that are considered necessary to implement a persistent storage application: create, read, update and delete.
Persistent storage refers to any data storage device that retains power after the device is powered off, such as a hard disk or a solid-state drive. In contrast, random access memory and internal caching are two examples of volatile memory – they contain data that will be erased when they lose power.
You’re likely familiar with CRUD operations as they underpin the behaviour of nearly every piece of software you interact with. Consider your mobile phone address book. We can add new people, we can look up entries, we can update their contact numbers, and we may even choose to delete people we’re no longer friends with.
Such operations are common across nearly all user facing software, from saving a file in a computer game, starting a new word process document, uploading or managing new social media posts, and managing podcast files.
Such operations are so commonplace that we expect to find them in most software, and we don’t often reflect on the fact that they represent a specific software design pattern. In user interface design, it may even be the case that a user interface is not viewed as complete until these operations are correctly implemented for users.
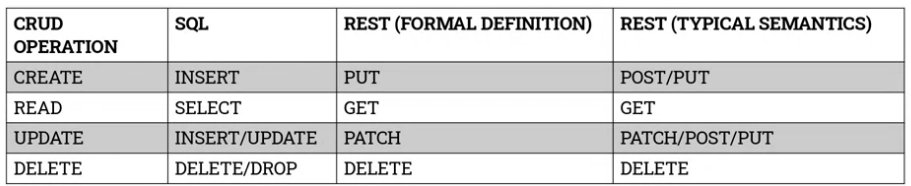
Each of the operations CREATE, READ, UPDATE, and DELETE can be mapped into specific SQL commands, namely INSERT, SELECT, INSERT/UPDATE, and DELETE.
We’ve briefly touched on HTTP user agent requests. Each HTTP user request contains a request type and it’s commonly one of POST, GET, PUT, and DELETE. These types can be easily mapped into the standard CRUD operations.
34.02 What is REST?
REST, short for Representational State Transfer, is a software and server architecture design pattern for creating web services.
Web servers and web services adhering to this design pattern are usually called RESTful web services.
There are 6 main features of REST:
Client-Server: REST application should have a client-server architecture. A Client is someone who is requesting resources and are not concerned with data storage, which remains internal to each server, and server is someone who holds the resources and are not concerned with the user interface or user state. They can evolve independently. Client doesn’t need to know anything about business logic and server doesn’t need to know anything about frontend UI.
Stateless: It means that the necessary state to handle the request is contained within the request itself and server would not store anything related to the session. In REST, the client must include all information for the server to fulfil the request whether as a part of query parameters, headers or URI. Statelessness enables greater availability since the server does not have to maintain, update or communicate that session state. There is a drawback when the client need to send too much data to the server so it reduces the scope of network optimization and requires more bandwidth.
Cacheable: Every response should include whether the response is cacheable or not and for how much duration responses can be cached at the client side. Client will return the data from its cache for any subsequent request and there would be no need to send the request again to the server. A well-managed caching partially or completely eliminates some client–server interactions, further improving availability and performance. But sometime there are chances that user may receive stale data.
Layered system: An application architecture needs to be composed of multiple layers. Each layer doesn’t know any thing about any layer other than that of immediate layer and there can be lot of intermediate servers between client and the end server. Intermediary servers may improve system availability by enabling load-balancing and by providing shared caches. eg if we go to Twitter, we just go to the URI layer, without thinking about the other layers that produce the results we see.
Uniform Interface: It is a key constraint that differentiate between a REST API and Non-REST API. It suggests that there should be an uniform way of interacting with a given server irrespective of device or type of application (website, mobile app).
Code on demand: It is an optional feature. According to this, servers can also provide executable code to the client. The examples of code on demand may include the compiled components such as Java applets and client-side scripts such as JavaScript.
34.03 Introduction to APIs
Web services that implement all of these six features are typically referred to as RESTful web services.
The APIs they present to user agents are called RESTful APIs. A RESTful API usually has three common features for clients.
- the application location is defined by some base URI that doesn’t change, eg something like api.example.com/api. That’s where the API calls need to be sent.
- we only use standard HTTP methods, such as POST, GET, PUT and DELETE.
- the API defines a media type that’s being sent to and from. The most common two types are text/json and text/xml, but you could define other media types.
34.04 Web clients and REST
We’ve looked at REST from the server side, as a list of six design requirements that allow a web server to be designed in a scalable, consistent, and client transparent manner. But how does it work from the web client?

In this table, we see two classes of URI. In the first class, we might consider that we are asking for a list of books, or individual items.
In our second class of URI, we’re asking for some computational operation to be performed. Here we have a potential operation called calculate sales. We’re expecting some calculation to be performed. This may typically be done asynchronously and then the results will be returned to us, to the client, at some later stage when the calculation is complete.
REST as a design is highly opinionated about what the types of HTTP method actually mean, so what it is that GET, PUT, POST etc mean?
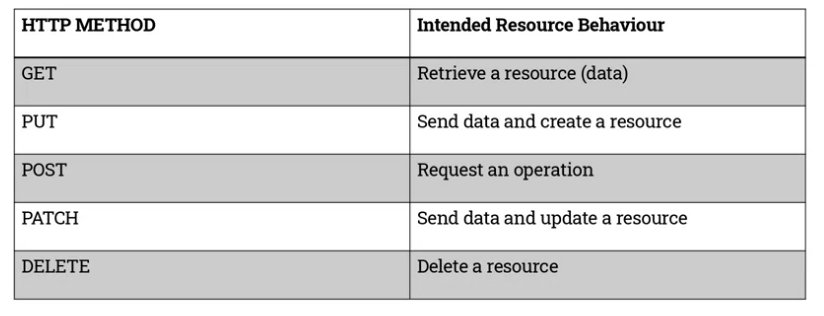
This is the theory of a well-designed RESTful API. In practice, people refer to their web applications as having a RESTful API only if they adhere somewhat closely to the six server-side architectural goals, and somewhat closely to these specific HTTP method invocations. This is more like what we see in practice:

Here’s a summary of the relationship between CRUD and SQL/RESTful APIs:
Wednesday 24 November 2021, 528 views
Next post: 35. Building a RESTful web service in Django Previous post: 33. Refactoring with generic views in Django
Advanced Web Development index
- 38. Writing API tests
- 37. Testing in Django
- 36. Class-based views in the Django REST framework
- 35. Building a RESTful web service in Django
- 34. Introduction to CRUD, REST and APIs
- 33. Refactoring with generic views in Django
- 32. Django validators
- 31. Django forms (2) – using the ModelForm class
- 30. Django forms (1)
- 29. JavaScript basics
- 28. Adding CSS to the template
- 27. Django templating
- 26. Deleting and updating records
- 25. Joins, filters and chaining commands
- 24. Using the ORM in views.py
- 23. Adding to the database by writing a script
- 22. Adding to the database with Django Admin
- 21. Migrations
- 20. ORM – work through example
- 19. An introduction to the Object-Relational Mapper
- 18. Altering the database
- 17. SQL functions and summaries
- 16. SQL Query performance
- 15. Queries and table joins in SQL
- 14. Inserts and queries in SQL
- 13. Good practice in relational database design
- 12. Limitations to database modelling
- 11. Building a database using SQL
- 10. Introduction to PostgreSQL
- 9. How to start writing a new application in Django
- 8. Building a lightweight project
- 7. Django URLs
- 6. Django templates
- 5. Django models
- 4. Django views
- 3. Creating a new hello app
- 2. Creating a new virtual environment
- 1. Setting up Django
Leave a Reply