10. ACID: Guaranteeing a DBMS against errors
10.01 Introduction to ACID properties
Let’s look at an example of a banking application handling money transfers. If we transfer £100 from A to B, these are the stages:
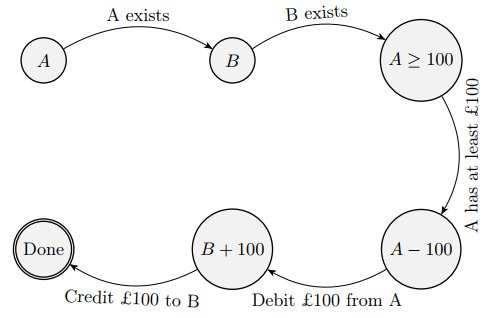
Any one of these states can fail – at a minimum we can lose power mid-transfer. The issue here is the entire set of state transition only makes sense as a full block.
If anything fails, we need to roll everything back, somehow.
Another bigger problem would be if A has two outstanding transactions happening at the same time. What happens if A has exactly £900 in the account and schedules two simultaneous transactions, one for B of £100 and another for C of £900?
We can resolve these problems by ensuring our system has the ACID properties.
ACID is an acronym for Atomicity, Consistency, Isolation, Durability – a set of properties of database transactions intended to guarantee validity of data despite any possible errors that may arise, including power outages.
A group of databases operations that, together, satisfy the ACID properties is referred to as a transaction.
Further describing the purpose of each of the 4 tenets of ACID we have:
- Atomicity guarantees a group of operations is treated as a single unit. This means that if any operation in the transaction fails, the entire transaction is considered to fail and the database is left unchanged.
- Consistency guarantees that a transaction can only migrate a database from one valid state to another valid state, maintaining any invariants.
- Isolation guarantees that concurrent transactions leave the database in the same state as if they were executed sequentially.
- Durability guarantees that once a transaction is committed it will remain committed even in the event of system failure (i.e. transactions are recorded in non-volatile memory)
A more simple summary of this:
- Atomicity – either the whole set of operations is performed or none
- Consistency – the database never shows an inconsistent state as a result of the processing of a group of operations
- Isolation – sets of operations will produce the same result as they would if they were running one at a time
- Durability – either all of the set of operations or none will be physically committed onto persistent storage
10.02 Transactions and serialisation
If we’re going to be able to make the guarantees that the ACID properties require, we’re going to need to treat a group of operations that have to be carried out en bloc in a specific way. The mechanism for that is called transactions.
Let’s imagine a three-stage transaction:
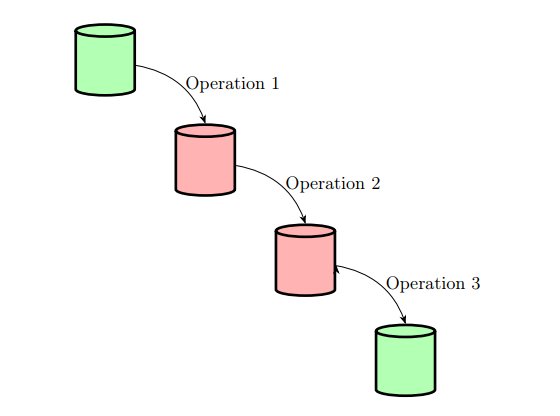
The database is only valid on green states, that is, either before starting operation 1 of after completing operation 3. The other two intermediary states must be considered invalid states and the database system should protect against those in the event of system failure.
Starting with Isolation, we can restrict access to data that might be affected by any operation in the block. In practice, the database system implements a lock that must be held in order to modify that particular set of data. This lock guarantees that no concurrent access to the data happens, thus forcing serialization.
Atomicity requires the implementation of rollback. This ensures that in case an operation in a block fails, we must be able to rollback to the state immediately before the block was started. In other words, we guarantee that the database returns to a green state in the event of a failed operation.
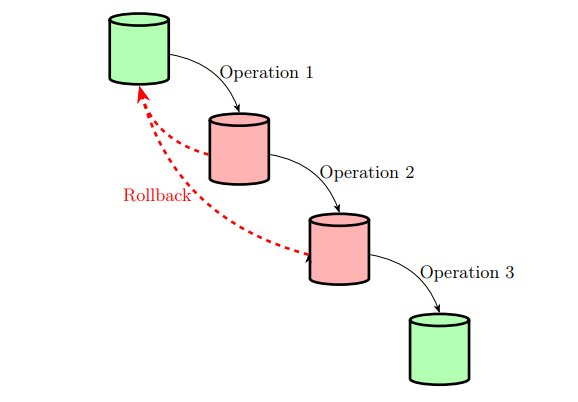
Durability means that valid states are reliably recorded. The obvious way of achieving that is to write both states to persistent (i.e. non-volatile) storage:
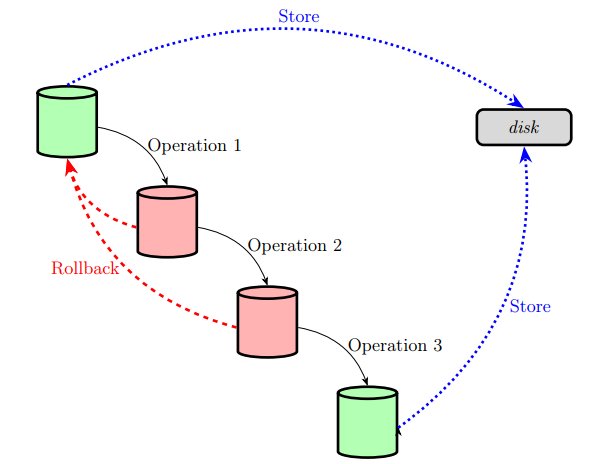
Consistency comes as a result of restricting access to intermediate states of the database. We only store initial and final states.
In practice, we only give operations access to the database if we know they won’t suffer side effects from this known inconsistent (intermediary) state of the database.
The mechanism to do that is called a Transaction. Once we decide that group of operations must be atomic, or carried out as a block, we declare them as a transaction by using START TRANSACTION; command. With that, any operations placed next until a call to COMMIT; will be treated as intermediate states of the database. In case of any errors, we can use the ROLLBACK; command to undo the inconsistent states.
So in other words we need to start a transaction; carry out the operations; and then either commit (if all good) or rollback (if there’s something we did wrong).
START TRANSCATION; SELECT ... INSERT ... UPDATE ... COMMIT; or ROLLBACK;
Some details to keep in mind:
- Data Definition Language can cause problems e.g. if we change the structure of a table in the middle of a transaction
- Checkpoints may not be as frequent as transactions
- Table locking is not absolute
Inconsistent Analysis is when two transactions access the same data. One has multiple queries which give inconsistent information. For example:
Transaction 1 – moving money from A to B
START TRANSACTION; UPDATE Balances SET Balance=Balance-100 WHERE Acc="A"; UPDATE Balances SET Balance=Balance+100 WHERE Acc="B"; COMMIT;
Transaction 2 – checking the balances
START TRANSACTION; SELECT Balance FROM Balances WHERE Acc="A"; SELECT Balance FROM Balances WHERE Acc="B"; COMMIT;
If these happen concurrently, it’s possible that transaction 2 could check A’s balance before transaction 1 takes place, and B’s balance after, which will obviously give an incorrect result.
Two options for solutions:
- Request for write access denied to Transaction 1. If one transaction is reading, no other transaction should be writing.
- Transaction 2 is given access to old states, while Transaction 1 updates new state.
Tuesday 16 November 2021, 508 views
Next post: 11. Malice and accidental damage Previous post: 9. Normalization example
Databases and Advanced Data Techniques index
- 26. A very good guide to linked data
- 25. Information Retrieval
- 24. Triplestores and SPARQL
- 23. Ontologies – RDF Schema and OWL
- 22. RDF – Remote Description Framework
- 21. Linked Data – an introduction
- 20. Transforming XML databases
- 19. Semantic databases
- 18. Document databases and MongoDB
- 17. Key/Value databases and MapReduce
- 16. Distributed databases and alternative database models
- 15. Query efficiency and denormalisation
- 14. Connecting to SQL in other JS and PHP
- 13. Grouping data in SQL
- 12. SQL refresher
- 11. Malice and accidental damage
- 10. ACID: Guaranteeing a DBMS against errors
- 9. Normalization example
- 8. Database normalization
- 7. Data integrity and security
- 6. Database integrity
- 5. Joins in SQL
- 4. Introduction to SQL
- 3. Relational Databases
- 2. What shape is your data?
- 1. Sources of data
Leave a Reply