5. Joins in SQL
5.01 Introduction
Joins are used to make queries that collect data from two tables.
The simplest form of a JOIN, called a Cross Join or a Cartesian Join, consists of simply listing all the tables we want to collect data from.
For example if we want the name of each person in four tables we could use this query:
SELECT Lead.name, Rhythm.name, Bass.name, Drums.name FROM Lead, Rhythm, Bass, Drums;
Let’s say we have 5 names in Lead, 6 in Rhythm, 7 in Bass, 9 in Drums.
Using a cross join will return every combination, i.e. 5x6x7x9 results in our results table.
Because the number of results grows so fast, we should carefully consider our constraints in the WHERE clause to limit the results.
Let’s say we have a relationship like this:
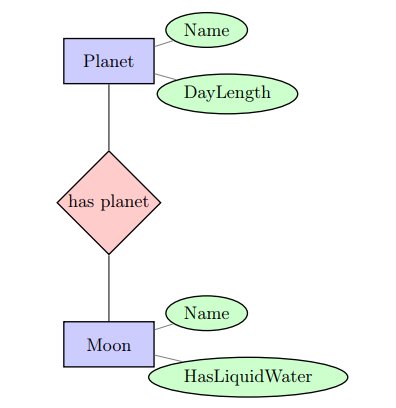
The example below is another way of executing a JOIN, called an Inner Join.
SELECT Planet.Name, Moon.Name, HasLiquidWater FROM Planet, Moon WHERE Planet.Name=Moon.HasPlanet AND DayLength < 11;
This will work but a more explicit (or better) version of the Inner Join would be:
SELECT Planet.Name, Moon.Name, HasLiquidWater FROM Planet INNER JOIN Moon ON Planet.Name=Moon.HasPlanet WHERE DayLength < 11;
The Outer Join is another type of JOIN. There are 3 types of Outer Join:
- Left Outer Join: Returns all the rows from the LEFT table and matching records between both the tables.
- Right Outer Join: Returns all the rows from the RIGHT table and matching records between both the tables.
- Full Outer Join: It combines the result of the Left Outer Join and Right Outer Join.
An example of a query:
SELECT Planet.Name, Moon.Name, HasLiquidWater FROM Planet LEFT JOIN Moon ON Planet.Name=Moon.HasPlanet;

5.02 Cardinality
Cardinality is how many rows in each of the tables that participate in a join match with how many rows in the other table.
It's often expressed in terms of a ratio (1:1, 1:n etc).
A 1:n relationship is where one row in table x joins with zero, one or more rows in table y
eg planets can have no moons (Mercury), one moon (Earth) or many moons (Jupiter)
A 1:1 relationship is where one row in table x joins one row in table y
This is quite rare. eg students only have one final project, so this is an example of a 1:1 relationship.
A m:n relationship is many to many - any number of rows in table x join with any number of rows in table y.
We use different letters to show that they aren't necessarily the same number.
eg Students on a degree programme may have multiple tutors; tutors may have multiple students.
Why should we care about cardinality?
Because it changes the implementation.
For 1:n relationships (or n:1, depending on which order the tables are in):
Use a FOREIGN KEY - place the primary key of the table with 1 value into the table with n values.
This is how you draw 1:n cardinality: (m = many, 1 = 1)
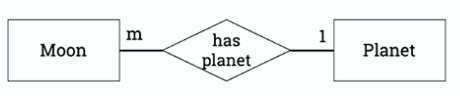
If a moon always has a planet, you can show this with a double line:

Here's an example of how to declare this:
CREATE TABLE Moons ( MoonName CHAR(20) PlanetName CHAR(10), Diameter INT, PRIMARY KEY (MoonName), FOREIGN KEY (PlanetName) REFERENCES Planets(PlanetName) );
The first PlanetName in the foreign key refers to the PlanetName in Moons.
For 1:1 relationships:

You'd normally put them in the same table if this is the case. But sometimes you might not and we'll look at this later.
CREATE TABLE Projects ( Student VARCHAR(100) Title VARCHAR(100), Mark INT, PRIMARY KEY (Student), );
For m:n relationships:
Take the example where students on a degree programme may have multiple tutors; tutors may have multiple students.
We need to create a link table to link up those many relationships between students and tutors.
CREATE TABLE TutorRole ( Student VARCHAR(100) Tutor VARCHAR(100), PRIMARY KEY (Student, Tutor), );
Tuesday 2 November 2021, 473 views
Next post: 6. Database integrity Previous post: 4. Introduction to SQL
Databases and Advanced Data Techniques index
- 26. A very good guide to linked data
- 25. Information Retrieval
- 24. Triplestores and SPARQL
- 23. Ontologies – RDF Schema and OWL
- 22. RDF – Remote Description Framework
- 21. Linked Data – an introduction
- 20. Transforming XML databases
- 19. Semantic databases
- 18. Document databases and MongoDB
- 17. Key/Value databases and MapReduce
- 16. Distributed databases and alternative database models
- 15. Query efficiency and denormalisation
- 14. Connecting to SQL in other JS and PHP
- 13. Grouping data in SQL
- 12. SQL refresher
- 11. Malice and accidental damage
- 10. ACID: Guaranteeing a DBMS against errors
- 9. Normalization example
- 8. Database normalization
- 7. Data integrity and security
- 6. Database integrity
- 5. Joins in SQL
- 4. Introduction to SQL
- 3. Relational Databases
- 2. What shape is your data?
- 1. Sources of data
Leave a Reply