22. RDF – Remote Description Framework
22.01 Introduction
Web technologies are built around the Document Object Model (DOM). Linked data also has a model, called Remote Description Framework (RDF). Here is the model:
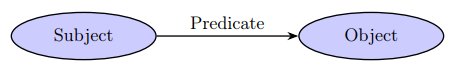
For example, we can state that Deimos orbits Mars. Predicate is usually a verb. This is called a triple, there are three elements, and they work in a very intuitive way.

More relationships can be added, for example Mars orbits The Sun, Mars is of type Planet, Deimos is of type Moon, and so on. In doing this we are moving objects to subject, so elements can be reused. By combining these together, we can produce a much larger graph:
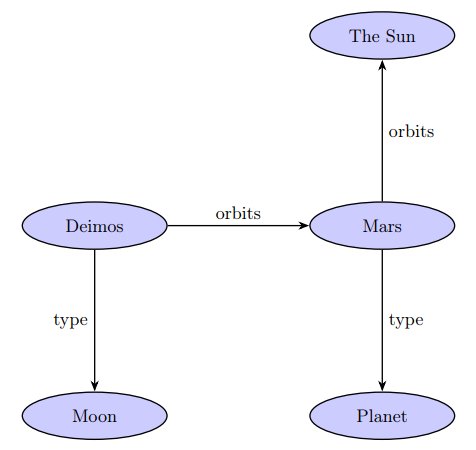
We can simplify the graph by combining triples into single units, if they are not linked elsewhere:

The triple stands on its own and isn’t connected to anything; we don’t have that top down tree structure that XML requires. We instead create our graph that’s decentralised based on lots and lots of small statements, that can start and finish anywhere in the graph.
There are challenges:
• Maintaining keys on the web
• Finding data on the web
• Sharing meaning
• Sharing entities
URLs are the key to solving these issues. Each node in our RDF graph represents a URL. The predicate on the edges in the graph can be replaced with, for example, the matching Wikidata link. Similarly, each entity in the graph has an entry in Wikidata which means they can also be replaced with the matching wikidata link.
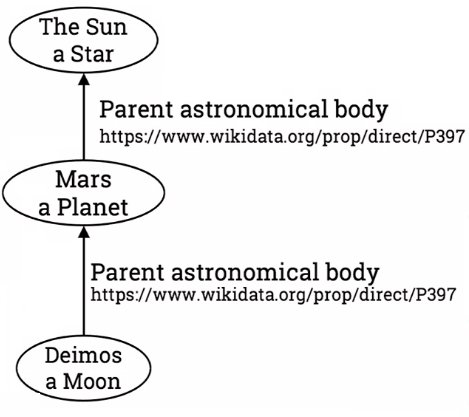
We can also replace the subjects and objects with links too:
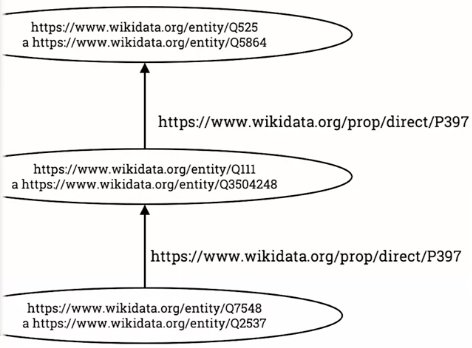
But note that while a subject must be a link, the object could be a link or something else, like a string, number or date. This is because at some point we need data. So a triple could be: Mars (Wikidata link) -> diameter (Wikidata link) -> 6779km (data)
If we spot that two different data sets are using the same using the same concept, we can actually create our own triple with a sameAs predicate that connect to you what is effectively talking about the same thing.
In summary, linking data requires that:
• Subject and Predicate must be URIs
• Object can be URI
– Or data: a string, number, date, etc
• sameAs predicates can connect URIs that represent the same thing
Dereferencing: The URL is unique – it’s guaranteed to be unique and so we can use it as a key. It doesn’t need to have a web page or any response to an http request for it to be usable.
But to get the best out of it, we need a URL that references so it gives us data when we request. It’s okay to build a dataset with URLs that do nothing. But far better is that when you request the URL you make an http request, what you get back tells you something about the thing that has that URL. So if I put that URL that we used for Mars into my browser, I’ll get information about Mars.
22.01 Serialisation
So far we’ve talked about RDF as an abstract model but we need a serialisation – to be able to write it out so that we can transmit it from one system to another.
There are lots of options as to what to use. It could be simple; easy to read and write; easy to mix into existing documents; easy to manipulate with software; or painful in every way.
Option 1: simple – n-triples (sometimes called n-3)
list the triples with <> around URLs, and a dot at the end of the triple. So something like this:
<https://www.wikidata.org/entity/Q111> <https://www.wikidata.org/prop/direct/P397> <https://www.wikidata.org/entity/Q525> .
These entries actually translate to Mars – item belongs to parent – Sun
Option 2: easy to read/write
An easy one to read is Turtle, often abbreviated to TTL.
We have ways of reducing repetition:
• You can use semi-colons to keep the predicate from the previous triple.
• You can use commas where objects have the same subject and predicate.
You can use the same syntax as in option 1 but you can also define some prefix statements so you get something like this:
PREFIX wd: https://www.wikidata.org/entity/ PREFIX wdr: https://www.wikidata.org/prop/direct/ wd:Q111 wdt:P397 wd:Q525 .
The dot at the end is important. Semi-colons give us the same predicate:
wd:Q111 wdt:P397 wd:Q525 ;
a wd:Q3504248 .
We can use a simpler-to-read ontology in the prefixes:

# He said “Deimos is a planet, and because we have a semi-colon we are still talking about Deimos, so Deimos is a satellite of Mars.” But Deimos isn’t a planet?
Option 3 – mixable
There is a technology called RDFa which allows you to use little fragments of RDF directly into HTML.
Option 4 – Load in JS
JSON-LD – not exactly a serialisation. It may look something like this:

In the curly brackets you can see the predicate becomes a key and the object becomes a value to that key. eg predicate = id, object = Mars.
Option 5 – painful: XML/RDF
It’s an XML serialisation of RDF which sounds good but it’s very ugly to read. It tries to put a graph structure into a tree structure and this doesn’t quite work.
Please avoid this!
Question: Which of the RDF serialisation languages is this?
PREFIX foaf: <http://xmlns.com/foaf/0.1/&g; <http://example.org/People/David&g; a foaf:person; foaf:knows <http://example.org/People/Kai&g; .
(a) n-triples
(b) ttl
(c) JSON-LD
(d) RDF/XML
Answer: (b)
22.03 Thinking in Graphs
When you draw graphs, for example:
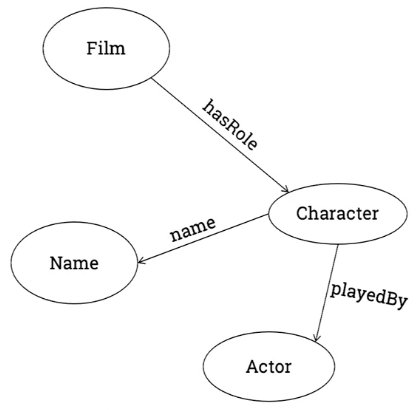
• No hierarchy (unlike JSON or XML which do have hierarchy)
• No order (you can draw them where you like)
• Every circle-arrow-circle is a triple
Wednesday 2 March 2022, 452 views
Next post: 23. Ontologies – RDF Schema and OWL Previous post: 21. Linked Data – an introduction
Databases and Advanced Data Techniques index
- 26. A very good guide to linked data
- 25. Information Retrieval
- 24. Triplestores and SPARQL
- 23. Ontologies – RDF Schema and OWL
- 22. RDF – Remote Description Framework
- 21. Linked Data – an introduction
- 20. Transforming XML databases
- 19. Semantic databases
- 18. Document databases and MongoDB
- 17. Key/Value databases and MapReduce
- 16. Distributed databases and alternative database models
- 15. Query efficiency and denormalisation
- 14. Connecting to SQL in other JS and PHP
- 13. Grouping data in SQL
- 12. SQL refresher
- 11. Malice and accidental damage
- 10. ACID: Guaranteeing a DBMS against errors
- 9. Normalization example
- 8. Database normalization
- 7. Data integrity and security
- 6. Database integrity
- 5. Joins in SQL
- 4. Introduction to SQL
- 3. Relational Databases
- 2. What shape is your data?
- 1. Sources of data
Leave a Reply