20. Transforming XML databases
20.01 Comparing them to relational databases
It’s an unfair comparison to compare XML databases against relational databases as they do different things.
XML is usually processed and used in different ways to most SQL databases. In practice, XML is often used in very different contexts. You wouldn’t expect normally to run, for example, rapid e-commerce systems using an XML database.
XML gives a different, looser structure; a tree is not an ideal structure for heavy cross referencing, whereas SQL is built around joins.
XML is harder to index; and supports richer searching and indexing. As is the case for MongoDB, an XML-based query can retrieve richer information without using joins than SQL can.
XML, like JSON, is usually parallelisable – they can be weblinks and are highly shareable.
20.02 Transforming XML: XML Pipelines
Transforming XML is the equivalent of a query. We can transform XML into another XML or into any other textual format. There are two main languages to perform these
transformations:
• XSLT
• XQuery
20.03 XSLT
The eXtensible Stylesheet Language Transformations, XSLT, encodes how we want to transform the XML source. In order to use it, we need the input XML, the XSLT transformations, and a XSLT Processor, the output of which is the new transformed text.
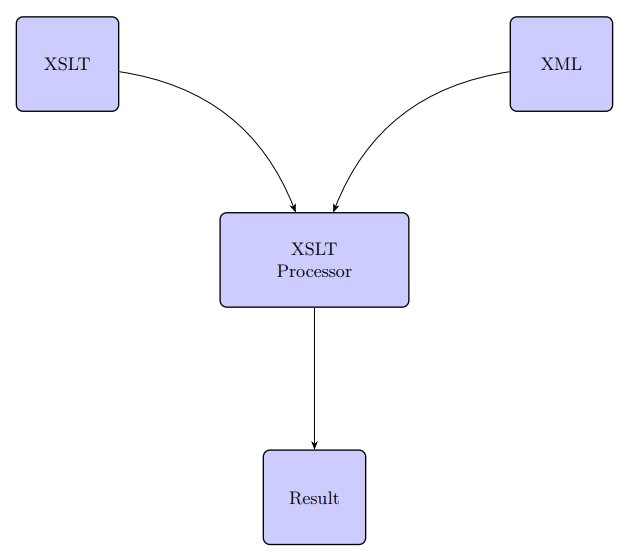
You have your original XML file and an XSLT file which tells you how to change it.
For example, here’s some sample XML:

We can draw this as a tree:
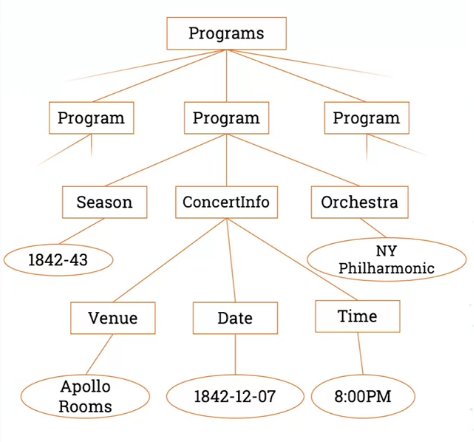
The way that XSLT work is through templates. What we do is we say when you’re walking through the tree, if you meet something that matches this particular pattern, I want you to return this value.

In this case, we’ve got a template which is set to match programs. When it finds an object in the tree, that’s programs, it will do what’s inside of this, which is to make a table.
We have a table; opening tag and closing tag and so to apply any further templates on the children of that node. It’ll find the programs node and then it’ll run look for templates on all the nodes that are child nodes to that. All that this does really is it has a parent table.
Then we’re going to need another template. Let’s have a template that matches program.

This one is going to give a row. When we find a program, we want to table row. Again, we’re going to apply templates for the children. It’ll find each Program (the second row in the tree); this is a template that’s likely to be repeated multiple times, and we’ll get one row for each program.

This template now finds the venue and puts it in a cell in the table row. The “value-of” venue in our XML example is Apollo Rooms.
20.04 XQuery
XQuery was developed alongside XSLT and works in a way that’s closer to how SQL works.
We provide a template with interspersed XQuery code.
For example let’s say we wanted to create the same sort of table from our XML example. We’d do it like this:
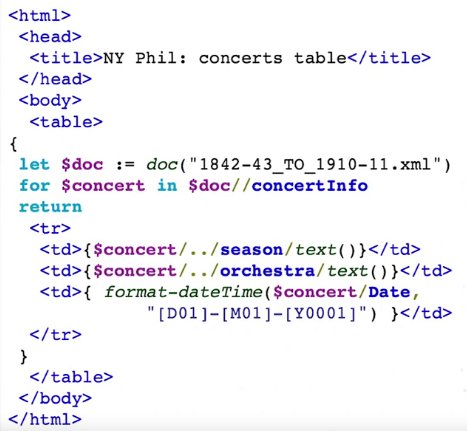
In XQuery terms, we talk about FLWOR (pronounced as flower) where:
F for clause
L let clause
W where clause
O order by clause
R return clause
Sunday 16 January 2022, 413 views
Next post: 21. Linked Data – an introduction Previous post: 19. Semantic databases
Databases and Advanced Data Techniques index
- 26. A very good guide to linked data
- 25. Information Retrieval
- 24. Triplestores and SPARQL
- 23. Ontologies – RDF Schema and OWL
- 22. RDF – Remote Description Framework
- 21. Linked Data – an introduction
- 20. Transforming XML databases
- 19. Semantic databases
- 18. Document databases and MongoDB
- 17. Key/Value databases and MapReduce
- 16. Distributed databases and alternative database models
- 15. Query efficiency and denormalisation
- 14. Connecting to SQL in other JS and PHP
- 13. Grouping data in SQL
- 12. SQL refresher
- 11. Malice and accidental damage
- 10. ACID: Guaranteeing a DBMS against errors
- 9. Normalization example
- 8. Database normalization
- 7. Data integrity and security
- 6. Database integrity
- 5. Joins in SQL
- 4. Introduction to SQL
- 3. Relational Databases
- 2. What shape is your data?
- 1. Sources of data
Leave a Reply