15. Query efficiency and denormalisation
15.01 Query efficiency
The bigger your database gets, the more users there are, the more complex your queries, the more likely you will get a slowdown.
The most expensive operations in a database are:
- Searching – often involve checking values on every entry in a table
- Sorting – ordering data by a given column, ascending or descending
- Copying – reading and writing a subset of the data points
So how can we speed it up?
If we know our data is already sorted, we can use Binary Search for finding what the row we’re looking for. eg if we’re looking for a name, we can put them in alphabetical order, then start at the middle and discard the first half or second half, then go to the middle again, etc.
Using sorted tables has the benefits of being as fast as tree indexes and requiring no extra space. However we can only choose one column to be the primary key.
Another option is use indexes, which usually is implemented as a B-tree (a self-balancing search tree) or as a hash table. The index can also be much smaller than the table itself, which may let us keep it in memory, rather than in disk.
B-trees generalize the concept of Binary Search Trees to nodes with more than two children, as such, it maintains all BST properties of space and time complexity. These properties are summarised below:

B-trees also support range searching and approximate searching.
In comparison, hash tables are very fast, as summarised below:
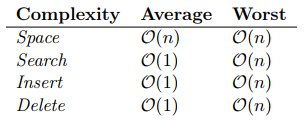
Hashing algorithms can be algorithms and hash tables can’t support range searching or approximate searching.
The order of the operations in a query has a big impact too. DBMS usually look at a query to see if they can optimise it so it makes the least number of operations.
Example:
The following query, run on a (theoretical) movie database, returns rows for the top ten highest grossing films. It lists film title, year, and the name, date of birth and gender of the first-billed actor.
What is the worst and best processing order that you can devise based on the query? How different would they be in processing time given the table sizes listed below?
SELECT Movie.title, Movie.year, Actor.preferredName, Actor.DoB, Actor.Gender FROM Movie, MovieActor, Actor WHERE Movie.ID=MovieActor.MovieID AND MovieActor.ActorId=Actor.ID AND MovieActor.billingOrder = 1 ORDER BY Movie.grossDollars DESC LIMIT 10;
Table sizes:
Movie: 7,000,000 rows
Actor: 10,000,000 rows
MovieActor: 100,000,000 rows
Answer:
The worst option is likely to be a cross join followed by sorting, followed by filtering, followed by limit. That will give 7×10^21 rows, which will take about O(10^23) to sort.
The best strategy is probably to realise that sorting and limiting only need happen on one table – Movie. Doing that first means that sorting takes O(10^9) operations. Applying the limit now gives us 10 results. The remainder of the joins now apply to only 10 rows, so should be fast. Whatever the indexing strategy, this shouldn’t be slower than the initial sort operation, so the whole will remain around O(10^9) operations, about 100,000,000,000,000 times faster than the worst strategy.
If the Movie table has a b-tree index by grossDollars, this query can probably be executed in under 100 steps.
15.02 Denormalisation
Normalisation can reduce disk reads by only reading the portion of data that is necessary for our application.
It can also reduce integrity checks and reduces storage requirements.
However, it increases the use of joins which can be expensive.
One way to avoid this problem is to denormalise – to glue our tables back together.
Dernomalisation is the act of putting duplicate structures back into the database to give fewer tables and simpler, faster queries. It’s about getting speed in exchange for fewer built-in guarantees about reliability of dat
Why would we do this? Because it reduces the number of joins we have to make and thereby reduces the complexity of queries. Effectively, instead of doing joined selects we have a cache. Now we have a version of the results of that select.
If we do this, it should be a deliberate thing after we’ve normalised a database. It is not a license not to normalise databases. We can think of this as “removing the safety net”.
But by doing this future joined selects can be immediately returned from the cache, rather than hitting the backing store again.
While this can give us some performance benefits, it’s risky for highly dynamic data.
An alternative approach is to employ Views. A View will act as a virtual table from which we can request data using regular queries.
Monday 10 January 2022, 450 views
Next post: 16. Distributed databases and alternative database models Previous post: 14. Connecting to SQL in other JS and PHP
Databases and Advanced Data Techniques index
- 26. A very good guide to linked data
- 25. Information Retrieval
- 24. Triplestores and SPARQL
- 23. Ontologies – RDF Schema and OWL
- 22. RDF – Remote Description Framework
- 21. Linked Data – an introduction
- 20. Transforming XML databases
- 19. Semantic databases
- 18. Document databases and MongoDB
- 17. Key/Value databases and MapReduce
- 16. Distributed databases and alternative database models
- 15. Query efficiency and denormalisation
- 14. Connecting to SQL in other JS and PHP
- 13. Grouping data in SQL
- 12. SQL refresher
- 11. Malice and accidental damage
- 10. ACID: Guaranteeing a DBMS against errors
- 9. Normalization example
- 8. Database normalization
- 7. Data integrity and security
- 6. Database integrity
- 5. Joins in SQL
- 4. Introduction to SQL
- 3. Relational Databases
- 2. What shape is your data?
- 1. Sources of data
Leave a Reply