23. Ontologies – RDF Schema and OWL
23.01 Introduction
You can’t properly share information without also sharing definitions, semantics and syntax.
The way that linked data is shared in the Semantic Web is through ontologies.
23.02 RDF Schema – RDFS
This is the simplest way of describing the syntax and semantics of your ontology of the basis of your linked data encoding.
example:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> <http://example.org/David> rdfs:type foaf:Person .
What does this mean? The example.org/David represents David, and that has an RDFS type of foaf:Person.
We create two prefixes for rdfs and foaf to define what these mean. foaf is a very old ontology for contact details.
We can also say:
foaf:Person rdfs:type rdfs:Class .
The fact that it can be a class is defined using rdfs:
We can also say:
foaf:Person rdfs:type rdfs:Class ; rdfs:subClass foaf:Agent .
In other words, a person can be capable of doing things. An Agent could be a person creating a file or a software agent doing this.
We can also subClass from multiple parent classes. So
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX geo: <http://www.w3.org/2003/01/geo/wgs84_pos#>
foaf:Person
rdfs:type rdfs:Class ;
rdfs:subClass foaf:Agent ,
geo:SpacialThing .
In this case the Person is not just a foaf Agent but also a SpacialThing within the geo ontology – this is some entity which occupies physical space. eg David is in London. (does he mean spatial?)
We are expanding what we are saying about an entity by pulling in other ontologies.
Another example:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX example: <http://www.example.org/> example:David foaf:knows example:Kai .
We are using prefixes to shorten example, and here this shows that David knows someone called Kai.
foaf:knows a rdfs:Property rdfs:domain foaf:Person ; rdfs:range foaf:Person .
Here, foaf:knows is not a class but a property. This means that “knows” is being used as a predicate, which has a Person as its domain and its range. Knows connects a person to a person (David knows Kai).
In the case of foaf:knows, I couldn’t use it to say “I know German”, as the documentation doesn’t allow it. The prefix has to point to the documentation so that you would know this; knows does not allow anything other than a human (Person) at the end of a triple.
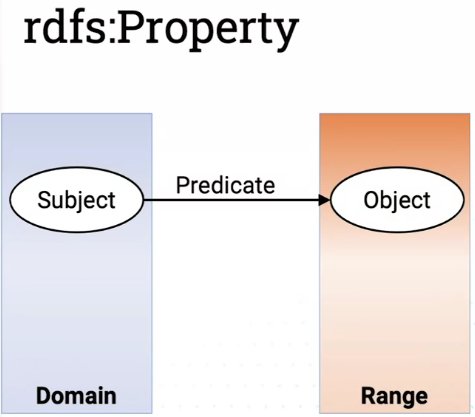
The subject must be in the Domain class and the object must be in the Range class.
Another thing that foaf gives is the ability to set a name:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX example: <http://www.example.org/> example:David foaf:name "David" .
We need both Davids here because example:David is pointing to the URL, where example: is a prefix representing the URL in the second line.
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX example: <http://www.example.org/> PREFIX rfds: <http://www.w3.org/2000/01/rdf-schema#> example:David foaf:name "David" . foaf:name a rdfs:Property ; rdfs:range rdfs:literal .
Again, in the foaf spec, foaf:name is a property because it’s standing as a predicate, and it has its range as a literal – it takes a string (“David”) as its object.
We can also do subclasses with properties:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX example: <http://www.example.org/> PREFIX rfds: <http://www.w3.org/2000/01/rdf-schema#> example:David foaf:name "David" . foaf:name a rdfs:Property ; rdfs:subProperty rdfs:label ; rdfs:range rdfs:literal .
foaf:name is a subProperty of rdfs:label – this is a general way of making a human-readable form. Name is a more specific version of that.
If you want to specify something more than RDFS can do, you can continue to use RDFS and then augment it with other languages. This language is likely to be OWL.
23.03 OWL – Web Ontology Language
This can be used as an extension to RDFS. It adds more complex constraints, and more richness.
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> foaf:Person a rdfs:Class ; owl:disjointWith foaf:Organization, foaf:Project .
When we say foaf:Person has type class in the ontology document for FOAF, we also say, for example, that the person is OWL disjoint with foaf:organization and foaf:project.
This is another way of saying, although we can mix and match classes, an object can be a member of multiple classes, it would make no sense at all for a person to be an organization, or for a person to be a project.
If we’ve declared something to be a member of the class person, and then we try to say it’s an organization, this is a logical inconsistency and the system should warn.
OWL allows us to talk about the logic of the system – spotting things that go wrong, and deducing things from the information we have.
OWL does give a distinction between object properties and data properties.
owl:ObjectProperty – a predicate connecting entities
owl:DataProperty – a predicate connecting an entity to data (a string, number, etc)
So let’s say David made a module. David and module are defined with a URL prefix ex.
foaf:made a rdf:Property,
owl:ObjectProperty ;
made is an rdf property, and also an object property because it connects an entity (David) to another entity (a module).
The triple would be ex:David -> foaf:made -> ex:module
We can reverse this with another foaf property, maker. So we could say the module was made by David like this:
ex:module -> foaf:maker -> ex:David
foaf:maker a rdf:Property,
owl:ObjectProperty ;
There is a relation here – the two statements are not independent of each other. So we can also say:
foaf:made a rdf:Property,
owl:ObjectProperty ;
owl:inverseOf foaf:maker ;
There is also the concept of an equivalent property:
foaf:maker a rdf:Property,
owl:ObjectProperty ;
owl:equivalentProperty
dc.creator .
So maker in foaf is equivalent to creator in Dublin Core (this is the first time we’ve heard about Dublin Core! It’s a library ontology.)
This is where we start to get very helpfully-shared meaning. So we might have chosen foaf to be our primary way of representing but we’d like to use some dc statements too.
Another very useful concept is owl:sameAs. Most of us have multiple URLs that represent us. sameAs allows us to declare an equivalent.
Let’s say David, who has a URL in ex, is the same entity as someone who has an ORCID iD – an identifier for people who are involved in academic writing. David’s ORCID iD could be 0000-0003-4151-0499. So our triple is:
ex:David -> owl:sameAs -> orcid:0000-0003-4151-0499
This is used a lot with things like Wikidata where they are connecting data sources.
There are also owl restrictions – see https://www.cs.vu.nl/~guus/public/owl-restrictions/
23.04 The Open World Assumption
We must be very careful of the OPEN WORLD ASSUMPTION. In a simple SQL database, we define truth and falsehood in terms of the relation. The relation is the data and the data structure.
If we do a search over the database, we can say that the result is correct or not correct. That the statement being made is true or not true based on the universe of that data.
If there’s a row that says, “David knows Kai,” then David knows Kai. If there isn’t, David does not know Kai.
Now, this works because we have defined the universe of knowledge as starting and ending with that database. We saw that with normalization as well, that when we’re talking about functional dependencies, we said, “Given the relation, is there a functional dependency?”
We can’t know whether there’s a functional dependency in the complete world, but we can normalize for the data we have or the data we expect to have.
The linked data in the Semantic Web world explicitly does not have that assumption. We can never know whether there’s a triple out there that talks about one of our URIs.
Because the URI is universal as an ID and because the web is the domain of the database, not our local copy, we have to assume that there can be other statements.
You cannot know, just because our list of friends of David does not include Kai, that it’s not true that David knows Kai. We would have to entertain the possibility that somewhere in the world, there’s a triple that has that information in it.
Likewise, we can say, “All swans are white” and that does not prevent someone from publishing a triple that says, “Here is a black swan.”
Although we can define logic and reasoning and define systems that work off that, we have to be aware that those constraints are not going to stop data that breaks those constraints being published.
If we say, “This particular predicate cannot take a subject of this form”, that does not stop someone publishing data of that form. We don’t get to send the police around and arrest them for not obeying our syntactic rules.
There’s a lot more on ontologies here: https://www.degruyter.com/document/doi/10.1515/bfp-2018-0025/html
Question: What sequence of steps can you see being taken in the process of modelling described in the article?
Answer: There’s no single formal model for how you go about modelling (ironically), but you should be able to see processes like:
Analysing the source datasets – what structures do they need? What do they have in common? What could they have in common with a little extra work?
Surveying and evaluating existing ontologies – What structures and concepts do they provide? How suitable are they? How adaptable are they to different needs?
Modelling and extending ontologies – How will the data be structured? What is missing from the pre-existing ontologies? How can new structures be added in a way that works well with the ontologies being imported?
Finally, the resulting model is likely to be formalised in OWL. This step is helpful, and supports documentation and reasoning.
23.05 Designing an Ontology
Designing a Web Ontology should be no different from designing the schema for your relational database. You do your modelling perhaps with Entity Relationship model, and then you implement it somehow.
There’s an element of extra care that we often take with a Web Ontology for multiple reasons. If your ontology is good, if your data model is good, it’s exposed to other people, they may start using it. You may accidentally or deliberately be creating a standard.
When using other people’s ontologies, it’s important to use it the way it was intended.
Whenever we’re tasked with designing an Ontology, there are a few principles we should follow:
• Use existing ontologies where possible
• Combine effort with others
• Test with real data
• Don’t get lost in rabbit holes, i.e. avoid adding unnecessary details
• Don’t be wrong
• Designing good ontologies take time
• Multiple viewpoints are vital
• Drawing helps a lot
• Be as explicit as possible to draw out problems
• Try out protege for ontology specification
– Webprotoge is a simpler version
Wednesday 2 March 2022, 526 views
Next post: 24. Triplestores and SPARQL Previous post: 22. RDF – Remote Description Framework
Databases and Advanced Data Techniques index
- 26. A very good guide to linked data
- 25. Information Retrieval
- 24. Triplestores and SPARQL
- 23. Ontologies – RDF Schema and OWL
- 22. RDF – Remote Description Framework
- 21. Linked Data – an introduction
- 20. Transforming XML databases
- 19. Semantic databases
- 18. Document databases and MongoDB
- 17. Key/Value databases and MapReduce
- 16. Distributed databases and alternative database models
- 15. Query efficiency and denormalisation
- 14. Connecting to SQL in other JS and PHP
- 13. Grouping data in SQL
- 12. SQL refresher
- 11. Malice and accidental damage
- 10. ACID: Guaranteeing a DBMS against errors
- 9. Normalization example
- 8. Database normalization
- 7. Data integrity and security
- 6. Database integrity
- 5. Joins in SQL
- 4. Introduction to SQL
- 3. Relational Databases
- 2. What shape is your data?
- 1. Sources of data
Leave a Reply